 |
 |
Пол Леру (Paul Leroux)
QNX Software Systems
[email protected]
Аннотация
Программные ошибки, присутствующие в поставляемой на рынок продукции, приводят не только к неправильному поведению и низкой степени готовности системы, но в результате и к недовольству клиентов, а следовательно уменьшают число желающих купить такую продукцию. К сожалению, традиционные методы отладки сами по себе влияют на работоспособность, производительность и правильное поведение отлаживаемой системы. Поэтому в настоящей статье исследуются технологии отладки и сбора информации о системе, которые сохраняют работоспособность системы, собирая, в то же время, данные, которые помогают диагностировать и разрешать проблемы отказов программного обеспечения.
Введение
В современной встраиваемой системе могут исполняться сотни программных задач. Все они используют общие системные ресурсы и сложным образом взаимодействуют друг с другом. Подобная сложность может являться "миной замедленного действия" для надежности по той простой причине, что чем больше размер системного кода, тем больше вероятность проявления ошибок в процессе эксплуатации. (По некоторым оценкам при поставке продукта, имеющего миллион строк исходного кода, в нем содержится, по меньшей мере, 1000 программных ошибок, даже в случае тщательной разработки и тестирования кода.) Ошибки в коде могут также представлять угрозу безопасности, потому что они часто являются точками, через которые могут проникать хакеры со своим вредоносным кодом.
Никакой объем тестирования не может полностью исключить подобные программные ошибки и "дыры" в безопасности, потому что никакой набор тестов не может предвидеть все возможные сценарии и варианты поведения сложной программной системы. Поэтому разработчики системы и программного обеспечения должны мыслить в рамках решения критически важных задач, создавая такую архитектуру программного обеспечения, при которой возможно наличие программных ошибок, но при этом система была бы способна быстро восстанавливаться после них. Не менее важно для разработчиков использовать инструменты и технологии отладки, при которых сохраняется целостность системы в процессе разрешения проблемных ситуаций. Инструментальные средства не должны вносить изменения, которые неблагоприятно или непредсказуемо воздействуют на поведение системы, особенно в случае, когда система активно предоставляет услуги пользователям. И после коррекции разработчиком ошибок любого программного компонента, инструменты отладки и базовая операционная система должны просто предоставлять возможность загрузки и проверки работоспособности исправленной версии, опять же без оказания влияния на общее поведение системы и на ее работоспособность.
Системная трассировка как средство получения наглядного представления
Когда сложная программная система работает медленно или неправильно, то из-за огромного количества внутрисистемных взаимодействий выявление истинной причины такой работы может оказаться невероятно сложной, даже труднореализуемой задачей. Например, если в многопроцессорной или в многоядерной системе запускаются и взаимодействуют десятки или сотни потоков, и если вдруг неожиданно блокируется один из потоков, то возникает вопрос, как выявить событие или взаимодействие, которое привело к такой проблеме? Без инструментальных средств, которые давали бы наглядное представление о ситуации на уровне системы в целом, может показаться, что причина кроется в одной части системы, хотя на самом деле она может находиться совсем в другом месте.
Дело осложняется еще и тем, что большинство традиционных инструментов отладки относятся к классу "агрессивных" (invasive), то есть они изменяют поведение диагностируемой системы. Например, если в отладчике сделана остановка только отлаживаемой программы, а не системы в целом, то это может привести к смене порядка исполнения системных операций. Такой феномен, часто называемый "эффектом пробника", может временно замаскировать протекание процессов и выдать "ошибки", которые возникают лишь во время отладки.
Конечно же, традиционные методы отладки по исходным кодам и профилирование приложений по-прежнему остаются важными инструментами для современных сложных многопроцессорных систем, проектируемых с использованием нескольких языков программирования. Но они полезны лишь тогда, когда разработчик уже определил, какой компонент или группа компонентов требуют коррекции. До этого разработчик должен вначале понять, как ведет себя система в целом. Например, в многоядерной системе у разработчика должна быть возможность определить, какие ядра обмениваются сообщениями и в какой последовательности. Разработчик должен также выяснить, какие процессы или потоки вовлечены в каждую транзакцию между ядрами, и проследить путь исполнения задачи при переходе от одного ядра к другому.
Ключевым подходом к получению наглядного представления о поведении системы является системная трассировка. При системной трассировке может использоваться целый арсенал инструментальных средств и технологий, включая:
- вызовы процедуры printf(), которые комментируют ход выполнения программы;
- средства вывода системной информации (например, команда top Unix), с помощью которых происходит слежение за созданием задач и использованием ресурсов;
- инструментальные средства в составе компилятора, с помощью которых возможно включение профилирования приложений и анализ покрытия кода;
- инструменты трассировки памяти, с помощью которых анализируется история использования памяти программами и возможна диагностика проблем, таких как утечки памяти и излишняя фрагментация памяти;
- инструментальные (отладочные) средства уровня ядра, которые обнаруживают события на уровне операционной системы, предоставляя точные временные траектории событий и отображая сложные взаимодействия между многочисленными процессами и потоками.
В большинстве случаев инструменты системной трассировки могут представить активность системы в виде линейной последовательности событий, позволяя разработчику быстро определить, какие события привели к тому или иному результату. В зависимости от стиля используемой трассировки разработчик может извлечь дополнительную информацию о согласовании процессов во времени или о прерывании задач. Эта информация может быть передана средствам анализа производительности системы или может быть использована в процессе отладки.
Рассмотрим, например, системный профайлер, инструмент визуализации, который входит в состав среды QNX® Momentics® IDE. Как и отладчик, который может выполнять трассировку сигналов управления от одного потока к другому в пределах одной программы, данное инструментальное средство дает возможность "увидеть", как взаимодействуют различные компоненты в системе, независимо от того, запущены они на одном процессоре или на нескольких процессорных ядрах. Если происходит что-то непредвиденное, то данный инструмент помогает выяснить, когда произошло конкретное событие, какие программные компоненты принимали в этом участие, что они в это время делали и, что наиболее важно, как можно интерпретировать событие.
В приводимой ниже таблице перечислены некоторые проблемы общего характера и описано, как разработчик может использовать системный профайлер для диагностики проблем.
| Проблема |
Техника использования |
|
Появление узких мест при межпроцессном взаимодействии (IPC)
|
Наблюдение за прохождением сообщений от одного потока к другому.
|
|
Конфликты ресурсов
|
Наблюдение за тем, как изменяются состояния потоков.
|
|
Замедление полной производительности
|
Просмотр использования ЦПУ для идентификации процессов или потоков, которые "съедают" большинство циклов ЦПУ.
|
|
Большая задержка в обработке прерываний
|
Просмотр событий пользователя с целью поиска потоков, приводящих к задержке, после чего в поток вставляются пользовательские события для выявления проблемы.
|
|
Избыточная миграция потоков в многоядерной системе
|
Наблюдение за тем, как потоки мигрируют от одного ЦПУ к другому.
|
Таблица 1. Использование системного профайлера для диагностики проблем общего характера.
Возможность заглянуть внутрь при сохранении работоспособности системы
Хороший системный профайлер ведет себя "неагрессивно". С его помощью можно заглянуть внутрь системы без необходимости модификации рабочего кода и с минимальным воздействием на поведение системы. При грамотной реализации системного профайлера разработчик сможет вести диагностику "живой" системы без прерывания её работы или без оказания заметного влияния на качество предоставляемых системой услуг.
Для подтверждения своей "неагрессивности" системный профайлер обычно ведет быстрое избирательное протоколирование системных событий, включая сообщения, вызовы ядра, изменения состояний потоков и прерываний. Написанный пользователем код при этом модифицировать не нужно, поскольку протоколирование событий осуществляется отладочной частью микроядра.
Возьмем, например, отладочную версию микроядра для ОСРВ QNX Neutrino®, которая представляет собой стандартное микроядро QNX Neutrino, куда добавлен небольшой модуль сбора событий. При запуске модуль перехватывает информацию о том, что происходит в ядре, генерируя события, привязанные ко времени и к действиям ЦПУ. Эти данные копируются в набор буферов, которые образуют кольцевой связанный список. Когда число событий внутри буфера достигает некоторого порогового значения, то специальная утилита протоколирования либо пересылает эти данные в другое хранилище на целевой системе (например, в ОЗУ, питаемое от резервной батареи), либо направляет их прямо в компьютер разработчика. Последний подход не требует наличия в целевой системе дополнительного хранилища данных.
При правильном построении отладочная версия микроядра может работать практически с такой же скоростью, что и стандартная неотладочная версия. Но и в этом случае в ядре существуют разнообразные механизмы, гарантирующие минимизацию воздействия на основную работу. Например, в микроядре можно разрешить вести журнал событий только при возникновении определенных условий. Можно также определить задаваемые пользователем фильтры так, чтобы процесс протоколирования касался только событий, представляющих интерес. Разработчики могут задать ведение журнала для такого (большого или малого) числа событий, сколько им действительно необходимо.
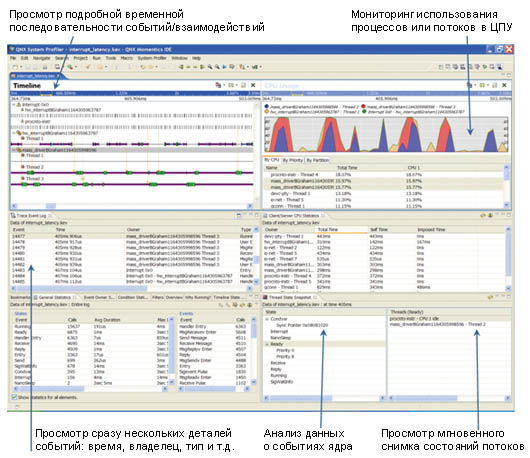
Рис. 1. Системный профайлер может собирать и анализировать данные, касающиеся вызовов ядра, аппаратных прерываний, изменений состояния потоков, межпроцессных взаимодействий и других событий системного уровня. Это дает возможность разработчику выявить ситуации взаимоблокировки, дефекты в логическом построении программы и другие условия, приводящие к деградации производительности.
Безусловно, всегда возможны ситуации, когда издержками ведения журнала событий (даже в небольшом объеме) будет воздействие на поведение системы во времени, хотя и минимальное. Для того, чтобы помочь разработчику определить, существует ли такая проблема, в отладочной версии микроядра должна существовать возможность вести протокол событий всех типов, включая и те, которые генерируются операциями ведения журнала событий. Отладочная часть версии микроядра должна быть сделана полностью вытесняемой. В этом случае высокоприоритетные задачи с жесткими временными рамками смогут вытеснить операции, ведущие журнал событий.
Даже при использовании фильтрации событий в реальном времени журнал отладочной части микроядра может содержать данные о тысячах событий. Поэтому в системном профайлере должна существовать возможность использования во время анализа дополнительных собственных фильтров. Таким путем разработчик может уменьшить объем записываемых данных, чтобы лучше рассмотреть представляющие интерес события.
Добавление определяемых пользователем событий
Часто бывает полезно задать синхронизацию с конкретными событиями приложения. Следовательно, в отладочной версии микроядра разработчик должен иметь возможность вставлять в систему трассировку задаваемых пользователем событий. Например, требуется задать трассировку времени, необходимого для обработки пакета. Для этого разработчик может создать событие, относящееся к моменту поступления пакета в систему и к моменту ухода пакета из системы.
Иногда данные, предоставляемые отладочной частью микроядра, оказываются столь подробными, что трудно понять, какие действия выполняются интересующей частью кода. Разрешить эту проблему помогут определяемые пользователем события. Размещая такие события в разных местах кода приложения или кода обработки прерывания, разработчик сможет построить последовательность событий, с помощью которой можно увидеть, на какие действия реагирует программа и какие участки кода за это отвечают.
Локализация проблем, связанных с доступом к памяти
При правильном построении ОСРВ может значительно упрощаться задача локализации и устранения множества ошибок, которые возникают в работающей системе, включая нарушения доступа к памяти. Например, в микроядре ОСРВ только малая часть кода фундаментальных объектов (например, сигналы, таймеры, службы планирования) реализована собственно в ядре. Все остальные компоненты – драйверы устройств, файловые системы, стеки протоколов, приложения пользователей – запускаются вне ядра как отдельные процессы в защищенной области памяти (см. рис. 2).
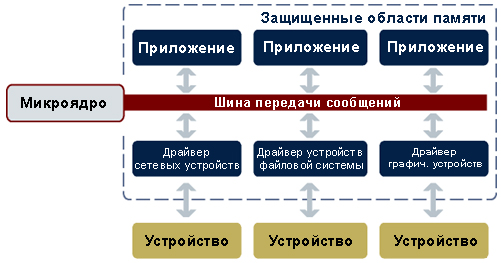
Рис. 2. В микроядерной ОС фактически может отказать любой компонент, и его можно будет перезапустить без отказа ядра в целом и без полного перезапуска всей системы.
Такой подход позволяет выполнить "тонкую" локализацию сбоев, предотвращая нарушение работы одного компонента любым другим компонентом. При этом возможно также выявить логические ошибки или ошибки работы с памятью с точностью до компонента, вызвавшего ошибку. Например, если в драйвере делается попытка обращения к памяти за пределами контейнера процесса, то ОС может немедленно завершить работу драйвера и восстановить используемые им ресурсы. Можно также точно идентифицировать место ошибочной инструкции или (с помощью символического отладчика) конкретную строку исходного кода. А тем временем, остальная часть системы продолжает свою работу, позволяя разработчику выполнить диагностику проблемы и сфокусировать свое внимание на её разрешении.
Поскольку микроядро позволяет выполнить "тонкую" локализацию сбоев, то это приводит к уменьшению параметра MTTR (Mean Time to Repair или среднее время восстановления) по сравнению с традиционными архитектурами ОС. Например, при отказе драйвера ОС быстро завершает его работу и перезапускает драйвер. Все это происходит в пределах нескольких миллисекунд, что на несколько порядков быстрее, чем при стандартных решениях, когда требуется перезапуск всей системы.
Использование программного сторожа для поддержания высокой степени готовности системы
Во многих встраиваемых системах устанавливаются аппаратные сторожевые таймеры для обнаружения факта "невменяемости" программы или аппаратуры. Обычно некоторые компоненты системного программного обеспечения вначале проверяют целостность системы, а затем сбрасывают специальный аппаратный таймер, чтобы подтвердить работоспособность системы. Если таймер не сбрасывается регулярно, то истекает время его работы, и происходит сброс процессора. Хорошо, если система сама восстанавливается от программной или аппаратной блокировки. Плохо, если систему нужно полностью перезапускать, что в некоторых случаях может занимать значительное время и приводить к потере информации.
Теперь давайте посмотрим, что происходит в системах с защищенными областями памяти. Если возникают нестационарные ошибки программного обеспечения, то ОС может перехватить это событие и передать управление процессу в пространстве пользователя, который носит название программный сторож. Данный процесс может далее принять разумное решение относительно того, как лучше всего произвести восстановление после отказа. В отличие от принудительного полного перезапуска – за это отвечает аппаратный сторож – программный сторож мог бы сделать следующее:
- аварийно завершить процесс, который привел к отказу из-за нарушений доступа к памяти, а затем просто перезапустить процесс без перезапуска остальной части системы;
ИЛИ
- завершить сбойный процесс и все связанные с ним процессы, заново инициализировать аппаратуру, переведя ее в "безопасное" состояние, и в необходимом порядке вновь запустить все остановленные процессы;
ИЛИ
- если отказ носит критический характер, то выполнить управляемый перезапуск всей системы и выдать звуковой аварийный сигнал системным операторам.
В отличие от своего аппаратного партнера, программный сторож дает возможность разработчику провести восстановление "с умом", программно управляя встраиваемой системой, даже если в управляемой системе по тем или иным причинам, возможно, перестали нормально работать несколько процессов. Аппаратный сторож может просто помочь системе восстановиться после аппаратного "заклинивания", но при программных зависаниях программный сторож предоставляет гораздо лучшие возможности по управлению.
Еще один положительный момент заключается в том, что программный сторож может вести мониторинг системных событий, которые невидимы для традиционных аппаратных сторожевых схем. Например, аппаратный сторож может проверить обслуживает ли некоторый драйвер конкретное оборудование, но может пройти еще много времени, прежде чем выяснится, правильно ли с этим драйвером работают другие программы. Этот пробел перекрывается программным сторожем, и соответствующие действия предпринимаются еще до того, как проблема обозначается собственно драйвером.
Создание дамп-файлов ядра для автономного анализа
При выполнении частичного перезапуска программный сторож может собрать информацию о природе программного сбоя. Например, если система содержит или имеет доступ к запоминающим устройствам большой емкости (флеш-память, жесткий диск, сетевой канал связи к памяти другого компьютера), то программный сторож может инициировать запуск утилиты создания дампа, которая создает хронологический архив дамп-файлов ядра.
В дамп-файле приводится информация, необходимая для идентификации строки исходного кода, которая привела к отказу процесса, а также данные по истории функциональных вызовов, содержимое элементов данных и другую диагностическую информацию. Разработчик может провести с дамп-файлом процедуру отладки, как будто работа идет на "живом" приложении целевой системы, проходя по шагам через стеки вызовов для определения события, которое привело к проблеме.
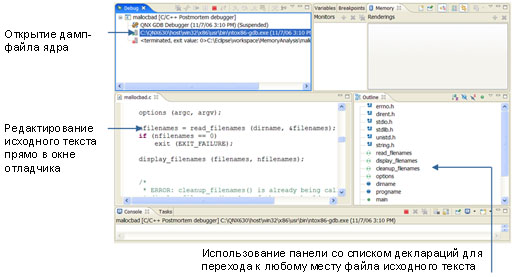
Рис. 3. Выполнение аварийной ("посмертной") отладки при работе с дамп-файлом ядра.
В некоторых случаях бывает достаточно просто как можно быстрее перезапустить процесс-виновник. Тогда вначале делается перезапуск процесса, а уже потом завершается создание дампа ядра. В некоторых реализациях программного сторожа, например, в администраторе критических процессов ОС QNX, предоставляется такой уровень управления, когда разработчику разрешается изменить порядок операций, захватить трассировку ядра и вставить туда возможности по принятию решения.
Используя разновидности утилиты создания дампа (службы, ответственной за захват информации ядра от "умирающего" процесса), разработчик может создать дамп-файл для конкретного процесса даже в случае, когда в процессе еще не возникло попытки обращения к запрещенным областям памяти. В утилите просто происходит "захват" процесса, дублируются в буфер его код и данные, а затем процесс "отпускается". Полученные данные переписываются утилитой в дамп-файл. Возникает вопрос – какая с этого может быть польза? Если работающая система ведет себя странно, то разработчик может зафиксировать мгновенное состояние системы для выполнения последующего анализа – без принудительного перезапуска и длительного вывода системы из рабочего состояния.
Обратная загрузка в систему исправленной программы
Выполняя "посмертный" анализ дамп-файлов ядра разработчик может выполнить отладку и исправление программы в автономном режиме, не снимая с обслуживания уже эксплуатируемую систему. Однако после корректировки исходного кода все равно остается задача обновления целевой системы с учетом нового кода.
Когда приходит время очередного обновления кода уровня приложения, то для большинства операционных систем никаких проблем не возникает. Фактически для некоторых операционных систем даже разрешается динамическое подключение к ядру новых служб, например, драйверов, протоколов. Тем не менее, поскольку такие службы впоследствии запускаются в пространстве ядра, то их трудно остановить, удалить и заменить на новые версии. Обновление в этом случае представляет собой определенную проблему, даже может оказаться вообще невозможным до тех пор, пока система в целом не будет остановлена и перезапущена.
Чтобы успешно разрешить эти проблемы, в ОС, как минимум, должна быть возможность динамической перезагрузки драйверов устройств и других системных служб. Но даже и в этом случае существует множество ситуаций, когда нужно обновить драйвер без прерывания работы службы, которая поддерживается драйвером. В результате нужно, чтобы ОС допускала запуск нового драйвера при работающем старом драйвере, а затем происходило бы плавное переключение работы службы и всех ее работающих функций на новый драйвер. Когда переключение произошло, ОС должна остановить работу старого драйвера и восстановить все необходимые для его работы ресурсы.
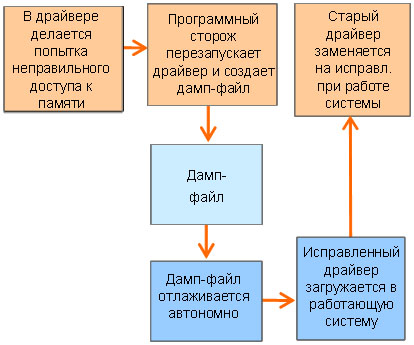
Рис. 4. Программный сторож может перезапускать проблемные компоненты автоматически, без вынужденного постоя или вмешательства оператора. Программный сторож может также генерировать дамп-файл процесса для последующей автономной отладки, что дает возможность разработчикам исправить ошибки, а затем загрузить исправленный фрагмент обратно в работающую систему.
Использование декомпозиции по времени для диагностики проблем при сохранении работоспособности системы
Технология декомпозиции по времени дает возможность отладки систем при одновременном предоставлении гарантий того, что критическим процессам будут выделены циклы процессора для их правильной работы в требуемых временных рамках. Используя эту технологию, разработчики помещают программы в виртуальные безопасные программные фрагменты, называемые секциями (partitions), и выделяют для каждой из них гарантированное количество процессорного времени. Такой подход к предоставлению ресурсов способствует:
- сдерживанию атак типа "отказ в обслуживании" (DoS);
- предотвращению монополизации ресурсов со стороны плохо написанных или вредоносных процессов;
- гарантированному получению доступа к ЦПУ со стороны низкоприоритетных функций;
- динамической поддержке новых приложений и служб со стороны системы с одновременным предоставлением гарантий того, что для существующих служб по-прежнему будут выделены достаточные для их работы вычислительные ресурсы.
И что наиболее важно, декомпозиция по времени дает возможность разработчику отлаживать систему, не лишая процессорного времени критические для работы процессы. Например, разработчик системы может зарезервировать 10% процессорного времени на работу отладчика и на любые связанные с этой работой коммуникационные процессы (см. рис. 5). Поскольку для любой другой подсистемы также выделяется гарантированная часть времени ЦПУ, то циклы, занимаемые отладчиком, не будут оказывать влияние на производительность или работоспособность системных функций ядра.

Рис. 5. При использовании технологии декомпозиции по времени разработчик системы может зарезервировать гарантированный процент времени ЦПУ, выделяемого для каждой из программных подсистем включая инструменты отладки.
Использование декомпозиции по времени может упростить процедуры ежедневного тестирования и отладки еще до того, как система поступает в эксплуатацию. Например, на этапе тестирования блоков ошибки в коде могут приводить к условиям, когда система выходит из-под контроля, что приводит к остановке процесса отладки. В таких ситуациях система оказывается заблокированной, и для разработчика единственным способом восстановления является полный сброс, а это приводит к потере полезной диагностической информации. Для предотвращения возможности развития такого сценария разработчик может создать программную секцию, для которой выделяется гарантированное время ЦПУ. Через эту секцию можно будет подключиться с помощью консоли для удаленной отладки. Тогда разработчик может продолжить отладку и собрать необходимую информацию для диагностирования проблемы.
Передача другим процессам не используемых для отладки циклов
Не все планировщики управления декомпозицией построены одинаково. В некоторых реализациях бюджет ЦПУ жестко определяется на все время работы, поэтому для секции в обязательном порядке выделяется все положенное ей время, даже если в это время нечего делать. В других реализациях применяется более гибкая политика, и неиспользуемые циклы ЦПУ динамически перераспределяются между другими секциями, которые могут использовать дополнительное процессорное время. При таком подходе ЦПУ используется максимально полно, и система имеет возможность удовлетворять пиковым требованиям по загрузке. Например, в ОСРВ QNX Neutrino используется адаптивная декомпозиция, при этом секция отладчика использует выделенный ей бюджет ресурсов ЦПУ только тогда, когда это необходимо. При простое отладчика планировщик передает неиспользуемые циклы другим секциям.
Разработчики могут очень просто ввести адаптивную декомпозицию в свои разработки. Она основывается на модели программирования промышленного стандарта POSIX, поэтому разработчики не должны будут переписывать существующий код или изучать специальную технологию программирования. Внутри секции потоки работают по традиционным правилам с планированием работы и прерываниями на основе приоритетов. Внутри секции работают все политики типа FIFO, циклическое (round robin) и спорадическое обслуживание. Фактически каждая секция представляет собой отдельный виртуальный процессор.
Декомпозиция как средство более быстрого восстановления и уведомления об ошибках
Для многих встраиваемых систем простой не допускается, система непрерывно должна быть доступна пользователям. Ниже дано формальное определение коэффициента готовности (КГ):
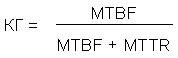
Параметр MTBF представляет собой среднее время между отказами, а параметр MTTR (mean time to repair) соответствует среднему времени восстановления после отказа или после разрешения возникшей проблемы. Говоря более простыми словами, можно повысить работоспособность (степень готовности) системы как путем уменьшения частоты отказов, так и путем уменьшения времени на восстановление после отказов.
Если во встраиваемой системе высокой степени готовности отказывает аппаратная или программная подсистема, то программные сторожевые схемы и другие функции автоматического восстановления должны вернуть систему в соответствующее рабочее состояние. Чем быстрее отработает функция восстановления, тем меньше будет значение MTTR и тем выше будет полный коэффициент готовности системы. Декомпозиция по времени может помочь в таком процессе, так как для функций восстановления гарантируется требуемый доступ к ресурсам ЦПУ.
В типичных системах, которые интенсивно используют ЦПУ, процессы слежения за состоянием системы с выдачей сообщений об ошибках не получают возможности быть своевременно запущенными. Гарантии доступа к ЦПУ за счет использования технологии декомпозиции по времени как раз и решают эту проблему и обеспечивают запуск типовых диагностических функций тогда, когда это предусмотрено. Эти функции могут, таким образом, обнаружить проблему и сообщить о ней до того, как это приведет к тяжелым последствиям.
В большинстве сложных случаев для "оживления" системы требуется вмешательство оператора. Чтобы это вмешательство было своевременным и эффективным, оператор должен быстро получить от системы уведомление об отказе и принять меры по диагностированию возникшей проблемы. Опять же, механизм декомпозиции гарантирует, что в системе есть достаточно ресурсов ЦПУ для уведомления оператора и для обеспечения гарантированного доступа к интерфейсу пользователя, будь то консоль, удаленный терминал или иной метод.
|
|
